Fake archive event
|
|
|
|---|---|
|
|
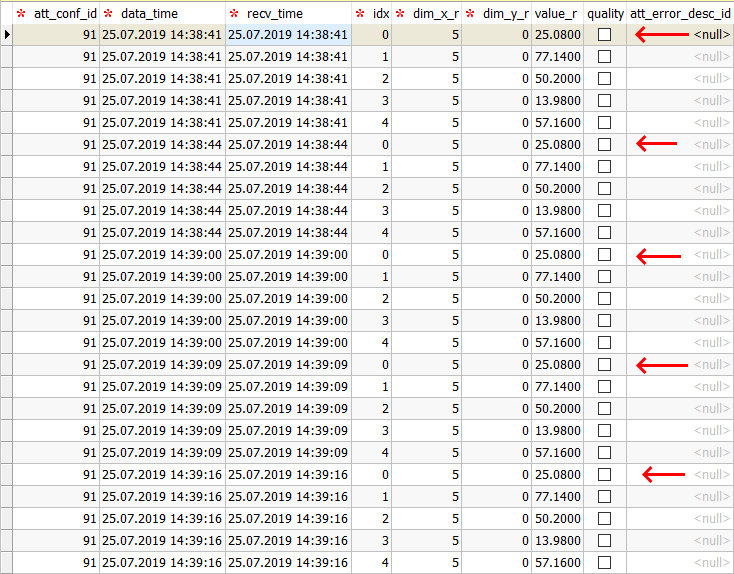
Hello. I have a DS with attributes which are archived by HDB++. For example, I have one command, which reads some hardware device, using Modbus DeviceProxy, and two attributes - scalar and spectrum DevDouble. The polling for command and attributes is 3000 ms. Absolute change for attrs is 0.1, periodic event is set to 600000 ms (10 min). Sometimes the device is off, so my DS can't receive new values from it. I have try-except block and when I receive the Timeout error after 3s, I set the state to FAULT and throw a Tango exception, doing nothing with attributes. I've noticed that for some reason I continue to receive successful "archive" events, which are definitely not periodic, because they appear randomly, and with the same values, so it's not "absolute change" also. With these events I also receive event with err=True and desc="The polling thread is late and discard this object polling." I've tested it on Python and C++, the same situation for both options. The HDB++ also receives events with data and archive it, so I have the same values in the DB and it consumes a lot of disk space. When I use State Machine functions "is_attr_allowed", I don't receive events, so it may be the solution. But is is a bug in event system? Or I don't understand correctly how it works? Can you give me some "best practices" for writing Device Servers for such situation, when the device is turning on and off? Do I have to always implement State Machine or check the state of the DeviceProxy or do something else? P.S.: example of archived values is in the attachment.
Attachments:
|
|
|
|
|---|---|

|
Hello, This is a very good question because it is a situation which is very often seen in practice. So, you have 1 command polled with a polling period of 3 seconds, and 2 other attributes polled with the same polling period of 3 seconds. So, the polling thread should be able to read these 2 attributes and to execute the polled command every 3 seconds. "The polling thread is late and discard this object polling" error you are seeing is a warning sent by the Tango polling thread which complains that it could not read these 2 attributes and execute the polled command within 3 seconds. When this occurs, an error event is sent to notify that the attribute could not be read on time. In your case, executing the command is taking at least 3 seconds (timeout) when the hardware is off, so there is no time to read anything else within these 3 seconds, so the polling thread complains. One thing you have to keep in mind is that the polling thread will not read all the polled attributes in parallel because there are some locks (Tango Monitor) involved. By default, you cannot read another attribute or execute a command while an attribute from the same device is already being read or a command from the same device is already being executed. This is also true for the polling thread. From what I see from the information you gave is that you are able to read at least the DevDouble spectrum polled attribute when the hardware is off. What happens is probably the following: The polling thread tries to execute the command or to read the scalar attribute first and this is failing due to the timeout (hardware not responding). The polling thread realizes it has no time to read the DevDouble spectrum polled attribute within the expected 3 seconds so an error event is sent. This error event should be archived in HDB++ too (we don't see it in your screenshot, maybe it is not when using HDB++ MySQL and spectrum attributes?). Then at some point the polling thread will read the polled DevDouble spectrum attribute successfully. Since the last event which was sent for this attribute was an error event (polling thread is late) and now it is reading a valid value, Tango considers that it should send an event with the valid value since it is different than the previous sent event, which was an error event. This is why you see many events with the same value, but there have been some "polling thread is late" error events in the meantime. Your problem is mainly a configuration issue. You should configure your system so these "polling thread is late" errors disappear in this specific case by increasing the polling period for instance or by reducing the command execution time or attribute read time (Using a dedicated thread to deal with the hardware for instance, or using the state machine indeed). In theory, one should consider the worst case when configuring the polling periods, also taking into account the other attributes and commands, which could take the Tango Monitor. I know that in practice, polling periods are often set to values which work well when the hardware is responding well but this could become problematic when you get these "polling thread is late" errors and you are using HDB++ (as it is now) because it is taking a lot of disk space at the end. I hope this clarifies a bit. Kind regards, Reynald
Rosenberg's Law: Software is easy to make, except when you want it to do something new.
Corollary: The only software that's worth making is software that does something new. |