Tango database
- ← previous page
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- next page →
|
|
|
|---|---|

|
Hi Jan & Andy, I perfomed some tests on my development machine. They are defintely not conclusive! My idea is to read the timing data recorded by the Databseds server. I tested in particular the performance of DbPutDeviceAttributeProperty2 , which has given us some trobules. There seems to be a slight advanatge of InnoDB + transactions: But I was not able to reproduce the "spikes", that is the occasional big delays, which we observe on our deployed databases. I used mysql Ver 14.14 Distrib 5.5.43, for debian-linux-gnu (x86_64) using readline 6.3 on Ubuntu 14.04. MySQL is used "out of the box" with the standard configuration provide by the distribution. |
|
|
|
|---|---|

|
Claudio, those are in fact good figures and what I implicitly hoped would be true all the time. Do the large delays occur when the tables are bigger or the number of clients increases? Your figures are different for InnoDB compared to Jan's. Do you have an explanation for this? Andy |
|
|
|
|---|---|
|
|
My hypothesis about the difference in performances: - client server, database and mysqld on the same host - host with large memory (24 GB) , i7-3770 CPU @ 3.40GHz , 8 cores The tests have been done with a more or less constant number of clients and rate of calls. It is interesting that the minimumtimes are very close for the two configurations and that the average time for InnoDB is about 1/2 of MyISAM. Claudio |
|
|
|
|---|---|
|
|
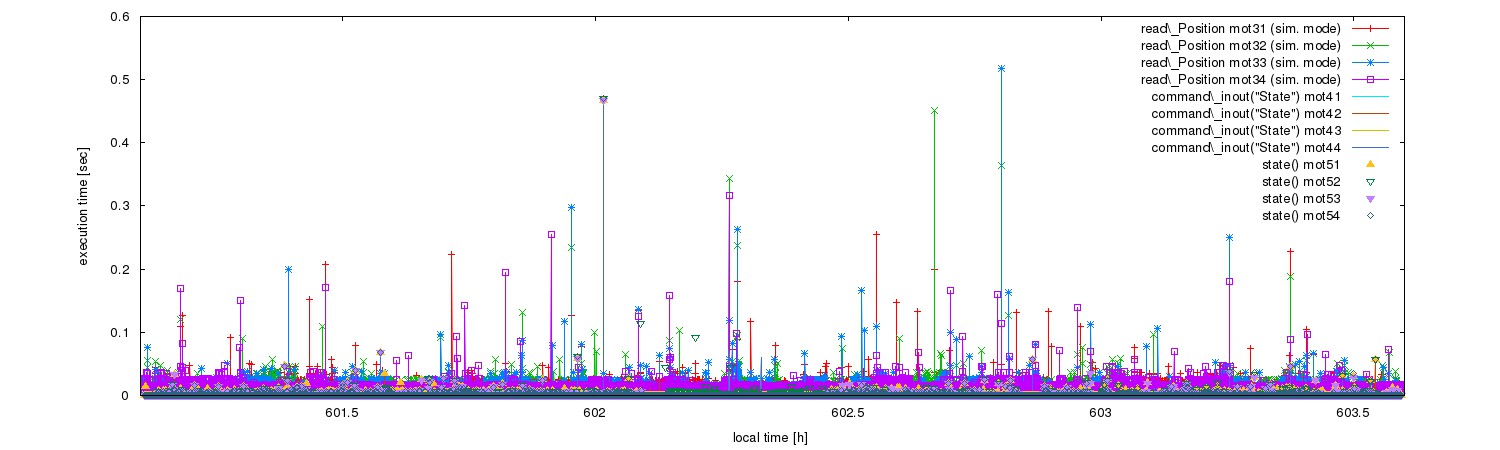
Hi, Yes indeed, my weak db host can be a kind of catalyser to create the spikes. My host has 8GB memory and and 4 cores. Additionally I'm running VM on one of the cores. For my previous plots, i.e. for innodb and myisam, the min, max and average are comparable. However, plots say something else (probably those 3 numbers are not enough to describe the spikes). I've replaced DELETE/INSERT by SELECT/UPDATE when only one attribute is updated but I don't see too much differences. Spikes have survived. Therefore, for a short time I've run a profiler on my mysql for db_put_device_attribute_property2() queries, i.e. SET SESSION profiling = 1 add some code to dump the slow queries and I get top 20 of my slowest queries for the short time run with innodb. To get top 20: To get more profile information Each profile dump consists of a three parts:
It seems that Updating/Sending data/update are the slowest tasks in spike queries. Bests, Jan
Attachments:
 355Kb 355Kb
|
|
|
|
|---|---|
|
|
Hi, I've just get an idea to replaced name LIKE "__value" to name="__value" I have to run longer tests but it seems that all my related to those SELECT/UPDATE queries spikes have disappeared. In SQL '_' denotes any character so if we use it with LIKE mysql searches for pattern, e.g. for name LIKE "__value" it search for all names where to first characters are arbitrary. And it takes time. I just wonder if it is not dangerous to use property names with '_' in LIKE queries? Theoretically such queries could select more properities than we want. Bests, Jan |
|
|
|
|---|---|
|
|
Hi Jan, this is amazing. I was thinking of replacing LIKE with = but I never thought of the impact the _ could have in the LIKE statement. This could explain a lot of the problems. It would be great if your results are conclusive. In the case we are talking about I do not see the need for the use of LIKE at all. This should be replaced by = in all the places where it is not needed. It would improve the performance for all the columns with primary keys too. BTW what kind of machine are you running your tests on - physical or virtual? How loaded is the machine when you run the tests? Maybe the LIKE statement is loading the cpu? Thanks for doing these tests. You might have solved the problem. Kind regards Andy |
|
|
|
|---|---|
|
|
Hi, After longer tests I see that the SELECT/UPDATE spikes are a little bit shorter and less frequent but they still exist. For tests I'm using Intel(R) Core(TM) i5-2500 CPU @ 3.30GHz with 8GB and 4 cores with debian wheezy. Before I was using VM to simulate multi TANGO_HOST environment but I havn't seen to much difference so I've switched if off. My DB tables are with innodb with standard setting plus innodb_flush_log_at_trx_commit=0 (which turns on buffering during writing to disk , with out it queries are slower) Quite often spikes are caused by Here, tere are my top queries. I add timestamps to see correlation in time between different queries. So it seems that they block each other. Thus, adding core to my machine could reduce the problem. Also the problem could be caused by common access to harddisk. Between 22:20 and 23:10 TSM disk backup is execuded and then I get the higher spikes So I don't thing this problem could be easily solved. Bests, Jan |
|
|
|
|---|---|
|
|
Setting innodb_flush_log_at_trx_commit=0 (which should be more saved) spikes are a liitle bit higher and dominated by and COMMIT or START TRANSATION queries. One can noticed it using mysql-slow-queries which gives: Rows_examined: 0 – corresponds to COMMIT or START TRANSACTION queries One can see that "UPDATE device_attribute_history_id …" locks for longer 61 rows (all I've got) of device_attribute_history_id table. |
|
|
|
|---|---|
|
|
Hi, I don't know how to speed up unsigned int device_attribute_property_hist_id = get_id("device_attribute",al.get_con_nb()); to unsigned int device_attribute_property_hist_id = 1; which messes up my history but it removes my spikes which have left. I have to wait again for my test but it seems that now my biggest spikes are of order 0.1 - 0.2 and corresponds to INSERT/DELETE into/from property_attribute_device_hist queries So to sum up I changed:
I don't know how to fix the last issue, any idea? And also it is not easy to replace LIKE by '=' because patterns are used in some application. Bests, Jan |
|
|
|
|---|---|
|
|
Hi, I've just realized that I don't know why but all my _history_id tables had size 61 (intsead of 1). That caused spikes of So after dropping rows on _history_id tables those spikes have disappeared. But why _history_id grows? Bests, Jan |
- ← previous page
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- next page →