Event loss issue
|
|
|
|---|---|

|
Dear all, many thanks for trying the sample code. I also run the tests with zmq 4.0.8 and found no issues. Cannot say at present if it was a problem with the specific zmq version (v4.2.0) or if I messed up the TangoDB in my laptop. I will use the current (apparently working) configuration and in case post if I have problems again. Instead the deadlock with pushing events from the code seem confirmed. Is this particularly affecting the AlarmSystem? Cheers, Simone
****************************************************************
Simone Riggi INAF, Osservatorio Astrofisico di Catania Via S. Sofia 78 95123, Catania - Italy phone: +39 095 7332 extension 282 e-mail: simone.riggi@gmail.com, sriggi@oact.inaf.it skype: simone.riggi **************************************************************** |
|
|
|
|---|---|

|
Team, Any update on this issue, we are facing the issue.
Regards,
TCS_GMRT |
|
|
|
|---|---|

|
Dear TCS_GMRT team, Is the issue you are facing the same as the one you reported on http://www.tango-controls.org/community/forum/c/development/java/attribute-events-gets-missed/ ? If yes, please comment directly on the forum topic you created. If not, please give us the maximum of details about your configuration and a good description of the issue you are facing and some ways to reproduce your issue. Otherwise it will be very difficult for us to help you. Kind regards, Reynald
Rosenberg's Law: Software is easy to make, except when you want it to do something new.
Corollary: The only software that's worth making is software that does something new. |
|
|
|
|---|---|

|
I can only agree with Reynald. Have you mixed up the issues? This issue was resolved as not being reproducible. Can you reproduce it? Under what circumstances? If you are referring the open issue you created please try to work consistently through the different proposals given by Reynald, Lorenzo and myself. We need to be able to reproduce your issue or have more information. Can you reproduce it in a test server and send us the code? Cheers Andy |
|
|
|
|---|---|
|
|
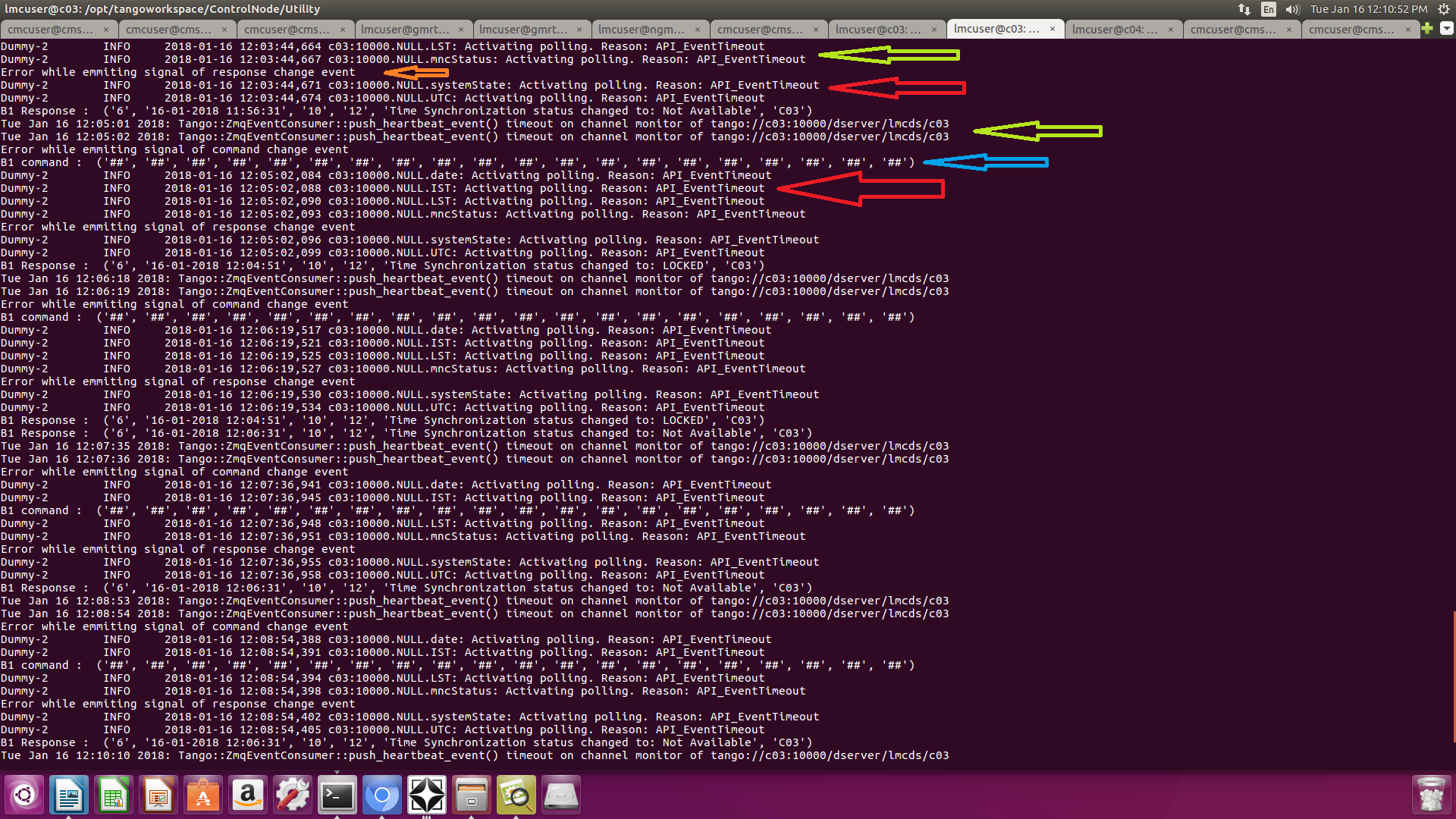
I can only agree with Reynald. Have you mixed up the issues? This issue was resolved as not being reproducible. Can you reproduce it? Under what circumstances?No both are two different issues for us. In this post, we are referring to the push_heartbeat event related issue. Our scenario: TANGO version : 9.2.2 ZMQ version : 4.0.7 OS : UBUNTU 16.04 LTS We have Taurus UI based on PyTango which subscribes to attributes of Java DS on change event. Along with this, we have displayed Taurus labels using a model to display the attribute values on GUI. We have observed the following error when both DS and GUI are running "push_heartbeat" event issue. Attached is the error screenshot for easy reference. Some explanation for the attached image: An arrow in Greenish Shade: The issue in discussion. An arrow in Red: We want to know what it is trying to describe. An arrow in Blue: Spectrum tango attribute initialized by "##" by Java DS during its init. An arrow in Orange: Change event response/error caused by the fluctuations (start-stop of DS) in the dserver/lmcds/c03 At this time GUI gets irresponsive and shows above error. We are unable to debug this issue as it is not following a pattern. When we check the status of dserver DS then it shows exported - false for 1 or 2 sec and again shows true. This gives a client event subscriber a change event (Arrow in Orange) and the issue occurs. We would like to know why dserver DS gets down, if someone has faced the similar issue? During this issue the GUI client freezes, we suspect that this might be one factor in the freezing of client. Other factors might be CPU & Memory usage. We would also like to understand more about the push_heartbeat concept. Note: LST, mncStatus, systemState, UTC … in the image are the Java DS Tango attributes. Additionally steps that we have performed: We tried installing ZMQ v4.2.3 but we hit another roadblock, meanwhile, we will be trying to fix the roadblock and update ZMQ to see if we still get this issue.
Regards,
TCS_GMRT
Attachments:
|
|
|
|
|---|---|
|
|
Hi, In Tango there is an heartbeat mechanism between the device server (DS) and the clients which subscribed to events on this DS. The DS will push regularly some special events (heartbeat events) to the clients to inform them it is still alive. The server should send these heartbeat event at least every 10 seconds. If a client did not receive any heartbeat event during more than 10 seconds, then it considers a reconnection must occur with the server, so the client will try to re-subscribe to the events every 10 seconds, until the server responds again. The reasons why the heartbeat was not received could be: - The server is dead - The network was down - The server has been restarted - … We know there are some issues with the Tango event system related to heartbeats sometimes when using different TANGO_HOST values on client and server sides, or when using network alias names in the TANGO_HOST values. In this case, you may experience reconnections every 10 seconds. I don't remember well but there might be some issues when using some uppercase letters in the hostnames as well. What you see on your logs (which are the logs from the client side if I understand well(??)) are push_heartbeat_event timeouts, which means no heartbeat event was received from the admin device tango://c03:10000/dserver/lmcds/c03 during at least 10 seconds. In red, I think you see a message from Taurus which switches to do some polling from the client side since it got notified the events were no longer working as expected. This means taurus no longer relies on events for the attributes from lmcds/c03 device server and tries to read the attributes directly at a regular period. So what you can check is: - is c03 a network alias name? - what is the value of TANGO_HOST environment variable on the server side. Are you using the same TANGO_HOST value on client and server side? - do you have any network issues between your client and server? - do you have a firewall in betweeen filtering some network ports? - is the machine where lmcds/c03 DS is running overloaded and cannot send heartbeat events because of lack of CPU resources? I won't be available until next Wednesday so don't worry if you don't get any answer from me before that day… In the mean time, other experts from the community could help you too…  Hoping this helps, Reynald
Rosenberg's Law: Software is easy to make, except when you want it to do something new.
Corollary: The only software that's worth making is software that does something new. |
|
|
|
|---|---|
|
|
It sounds like you are not getting events at all. Probably due to the TANGO_HOST issues mentioned by Reynald. Can you try all he suggests and start atkpanel on your device to see if it receives any events. You will see this in the Debug panel. You should see 0 events received and you should see the same errors in the Error tab as the ones you have seen in the C++ client window. I am not sure changing the zmq version will help but it is worth a try. This will confirm if events are working at all or not. Andy |
|
|
|
|---|---|
|
|
- is c03 a network alias name?Yes , co3 is the hostname of system - what is the value of TANGO_HOST environment variable on the server side. Are you using the same TANGO_HOST value on client and server side?- Both server and client are running on same system using same TANGO_HOST. (TANGO_HOST = c03) - do you have any network issues between your client and server?No, as they are running on the same system sharing same network. -do you have a firewall in betweeen filtering some network ports?- Firewall service is currently inactive. - is the machine where lmcds/c03 DS is running overloaded and cannot send heartbeat events because of lack of CPU resources?- Yes, sometimes we face CPU overloading issue at our setup. Along with this we are working on the suggestion provided by andy i.e. testing with atkpanel. We will provide you the updates about that.
Regards,
TCS_GMRT |
|
|
|
|---|---|
|
|
TCS_GMRT- is c03 a network alias name?Yes , co3 is the hostname of system Cheers, Lorenzo |
|
|
|
|---|---|

|
Hi all, I just wanted to add one more idea to check. I think that the API_EventTimeout can happen as well in case you have a long callback (more than 10 s) subscribed the an attribute. Or a burst of events that their callbacks will make the event consumer thread not able to handle the heartbeat event on time. Please experts correct me if I'm wrong. Just to discard this one, do you add your own listeners to the taurus models? Or maybe directly subscribe to the events using PyTango? As Reynald explains, in case of the API_EventTimeout, Taurus enables its own polling for these attributes, which eventually gets disabled whenever a correct event arrives. What makes me think that your client finally receives the events correctly is that the API_EventTimeout appears somehow periodically, more or less every 1m 20s. I would say that, in between, Taurus disables the polling and relies again on events. But it is hard to say without debugging. Maybe you could try to enable debug logs in Taurus. Either use the –taurus-log-level=debug when starting your GUI or set it programmatically with taurus.setLoggingLevel(10). Cheers, Zibi |