TdbArchiver - efficiency issues when attributes are delayed
|
|
|
|---|---|

|
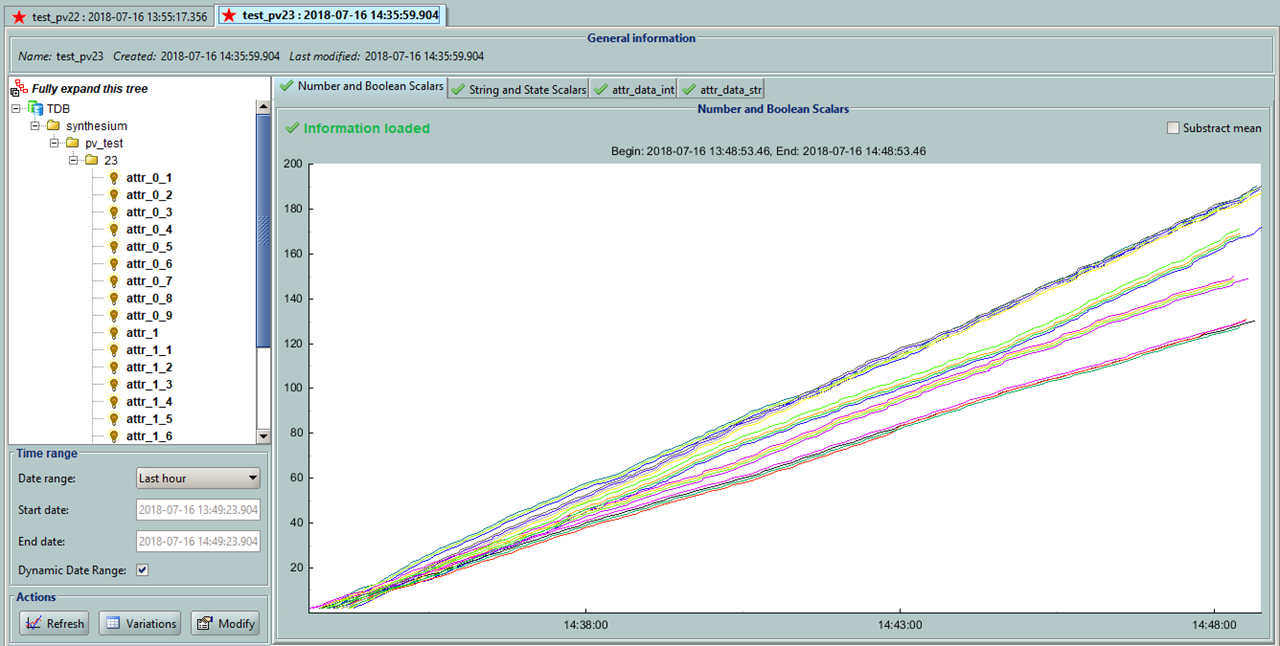
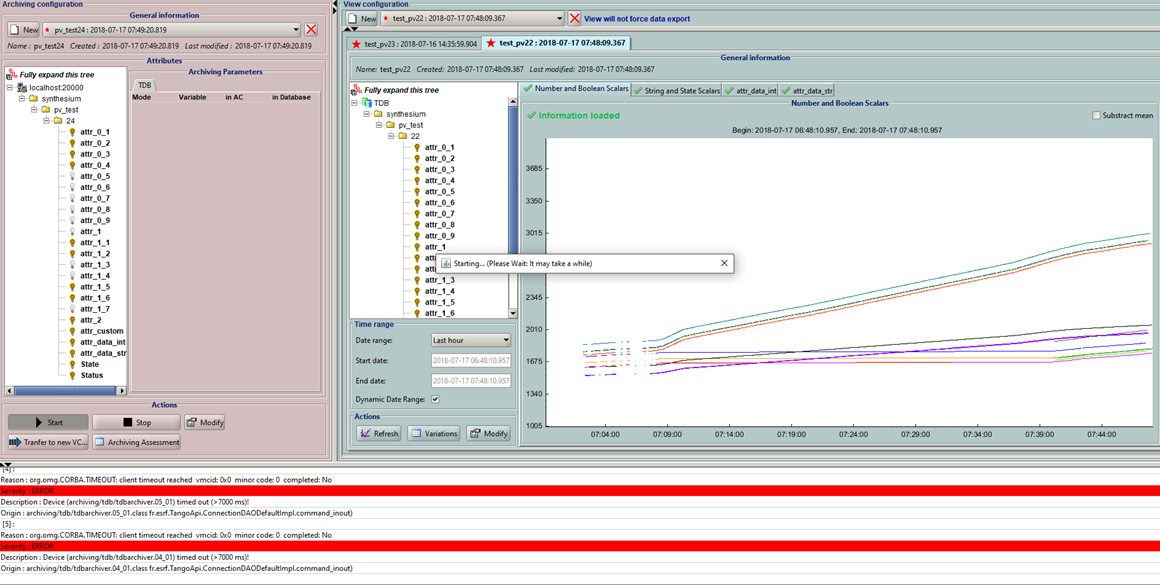
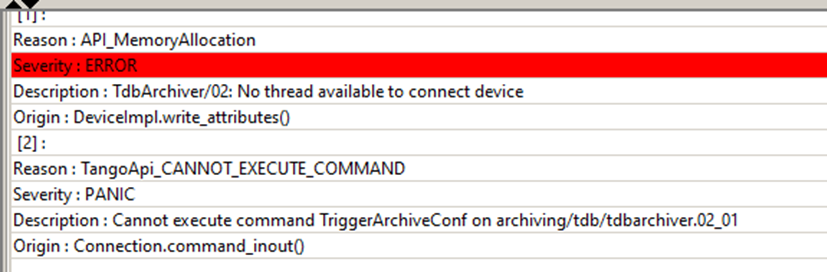
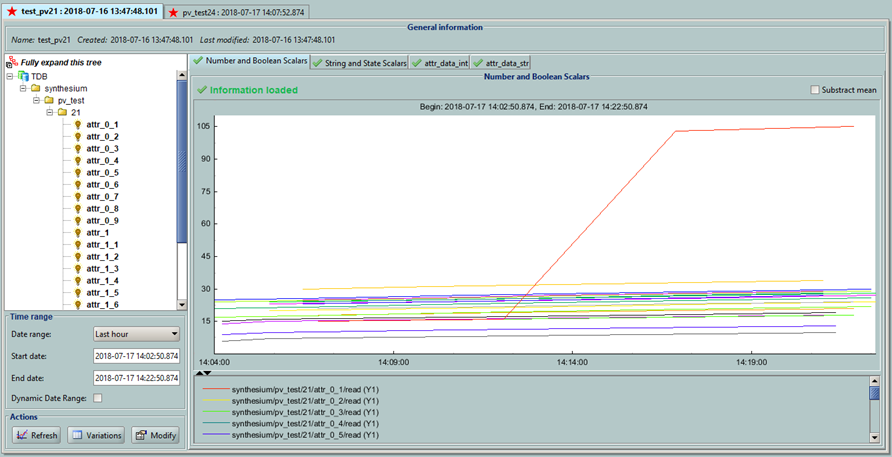
Hello Tangoers! I am facing a quite strange problem since I increased the number of devices from which TDB archivers collect data. So I have 5 instances of tdbArchiver and each of them has one device assigned. Then I have 3 instances of a dummy device server, which consists of 18 attributes(9 have 100msec delay and other 9 have 200msec delay on read). Archiving was defined on all atributes of these 3 instances one by one - gathering data periodicaly 1000msec. [3rd_device.png] As long as I was using only 3 of devices, data was collected as quite normal. So I decided to add 4th instance with a same delayed device. But started getting timeouts while Starting archiving. [4th_device.png] After about 8th click on Start button it managed to start archiving of all atributes. Then I added 5th device and same scenario. But I got a very strange error message on the logs. Appeared only ones or twice. [error_message.png] After all I also managed to start archiving on 5th dummy instance (had to click Start button like 10 times). But what is the most interesting suddenly archivers was collecting data not using a periodical way of 1000msec, but sometimes even 6-9minutes to archive attribute's value. I managed to notice it, because I increase the value which is returned by attibute by 1 on read. [delayed_archiving.png] As you can see on the screen above: Read was done about 14:11 and next 14:17. (The red line) Value was increased using Jive at about 14:12-14:13. Maybe you can point me, what do I do wrong? How to solve the problem when we have to archive data on devices, which returns its data after 100-200msec on read? In the very beginning I was using one instance of TdbArchiver which had like 10 archiver devices defined, but it all was running inside one instance process and I couldn't even start the archivig on more devices because of timeouts which I was getting. This is configuration of my environment: Tango 8.1.2 Archiver 15.2.1 PyTango 8.1.6 Python 2.7.14 Windows 10
Regards,
Jagoda
Attachments:
|
|
|
|
|---|---|
|
|
Hello Jagoda, At SOLEIL, we have a lot of TDB archiving (62 instances, each with 5 devices, each device archiving around 80 attributes), and we have never encountered this kind of issue. The only explanation I have is that you may have performance issues. Did you have a look at your machine load (memory, CPU, network, disk I/O, …)? for the archivers? for the archiving database? for mambo? Best Regards, Gwenaëlle. |
|
|
|
|---|---|
|
|
Hi Gwenaëlle, I was helping Jagoda with the issue. One part of the solution was to setup longer polling period on attributes (to more than 1.4 x sum of responses time). However, it was a computer performance issue, too. The performance drop was caused by extensive number of TDB temporary files (windows was not even able to list the files in the folder). Is there a suggested way to deal with these files? My first thought is to mount the temporary folder as a ramdisk. Best regards, Piotr |
|
|
|
|---|---|
|
|
Hi Gwenaëlle, I fully appreciate your answer and indeed we had some performance issues, which unfortunately appear only on Windows system. Hopefully, Piotr helped so I could move on with archiving. We increased the polling time, so archivers started to collect data properly and without losses. Another thing which might be very useful for Windows Tango users, to keep in mind that one has to manually remove files in C:\tango\TdbArchiver folder. It can be done for example by creating Windows Scheduler task, which periodically runs a script. This script would remove files older than 3minutes or even less - like 2minutes, just to be sure we won't remove files which might be currently in use by some of archiving services. Anyway… Piotr, thank you so much for help :) Best regards, Jagoda 
Regards,
Jagoda |